为什么不要用覆盖同名文件的方式来更新资源?
TL; DR
- 更新文件不要覆盖旧文件
- CDN缓存刷新不靠谱:可能刷不掉,刷掉了无法验证
- 运营商黑盒代理:怎么缓存不知道,无法验证
- 浏览器缓存不好清:存量用户缓存更新靠过期,强制更新不可取
这是一个前端工程化的老问题了,把静态资源和动态页面分开放在CDN和服务器上,上线时如何保证两边同步上线?这篇文章讲得很清楚,结论就是用 Webpack、FIS 等工具打包文件,得到带 hash 文件名的文件进行部署,而不是直接去覆盖线上文件。面试时问到这类问题,候选人一般也能给你扯出个子丑寅卯来。但实际工作中,某些项目前后端分离得连上线都是互相独立的,或者说后端嵌入一个 js 地址以后就不再关心前端怎么更新了,前端更新就是去覆盖固定的 JS 地址。假设说这个 JS 先于后端更新并兼容后端当前版本和更新版本,那么也就不存在后端更新跟前端对不上的问题,看起来很完美,但现实并不是这样,往往出现一些很玄学的问题。本文就从另一个角度来说一下为什么要坚持“更新不能覆盖文件”原则不动摇。
在具体说这个原因之前,不妨让我们来思考一下这个问题:从浏览器发起GET请求到接收到响应,这中间发生了什么?忽略 DNS 查询等操作,只考虑请求的流向。首先当浏览器发起GET请求(后称“请求”)时,浏览器会首先检查本地是否存在这个请求URL的缓存,如果有缓存且缓存没有过期则直接响应缓存内容。如果没有命中缓存,则浏览器真正发出请求。请求可能会经过浏览器的网络代理(如果有配置的话),代理这一层又会对请求做一次判断,是继续发送请求还是直接响应内容。经过了浏览器网络代理之后,再往后可能还存在操作系统的代理、路由器上的代理、运营商的代理、CDN(也可以理解成是一层代理)。(部分代理在 https 下失效)
+---------+-------+ +------------------+ +----------------+ +-----------+ +--------+
| Browser | Cache |-->| OS/Browser Proxy |-->| Operator Proxy |-->| CDN Proxy |-->| Source |
+---------+-------+ +------------------+ +----------------+ +-----------+ +--------+
由此可以看出,一个请求要经过多少层才能真正到达源站,而这中间的任何一层都可以“擅自”决定请求继续下去还是马上返回内容。一般来说,指导代理服务器如何缓存内容的就是 HTTP 响应头,但具体代理服务器的实现是否遵循规范就不得而知了。通常情况下,代理服务器如果要对资源进行缓存,至少会使用完整的请求URL作为缓存key,讲究一点的还会加上 Vary 指定的字段一起作为缓存key,像 Nginx 或 Apache 的代理模块都提供了丰富的配置;也有极少数非常离谱的——比如某城宽带配错代理把不同路径的文件当做同一个文件响应——的情况;而CDN一般会有开关允许 URL 过滤 queryString 后作为缓存key。所以当你把源站的文件覆盖后,其实是无法保证这个覆盖更新能够马上在所有用户的设备上生效的,很有可能用户下次访问时用的还是本地浏览器的缓存或是某一层代理的缓存,而不是最新的文件。

那这么多层代理,到底哪一些是前端可控的呢?很遗憾,并不多。当前端上传资源的时候,其实只是在操作源站。源站文件更新了,并不能马上影响到 CDN 以及往下的各层。理想情况下,如果每一层代理都遵循 HTTP 头指定的缓存时长自动过期的话,可能覆盖更新能够在缓存到期后逐渐生效,这具体取决于源站和CDN的缓存设置。比如百度云和腾讯云的 CDN 默认缓存时长都是 30天,也就是说覆盖更新的文件可能要等 30 天才能在用户的设备上生效。
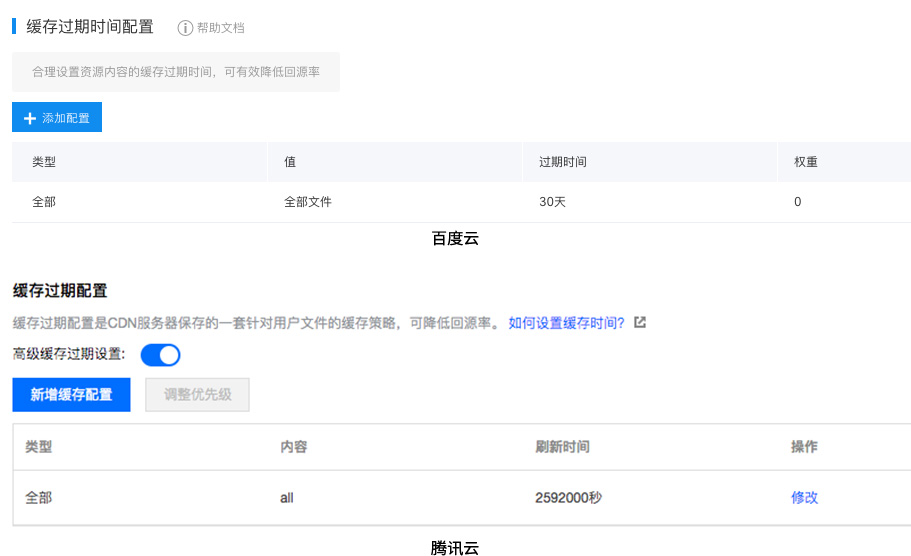
采用这种覆盖更新方式,前端唯一能做的就是去更新CDN的缓存,好在CDN一般都提供了强制刷新缓存的功能。但这一方式也存在局限性,百度云和腾讯云的刷新界面上都提示说“刷新任务生效时间大约需要5分钟”,这对于修复紧急bug来说不算短。而在实际使用时,常常会发生一些不可思议的现象,比如一个URL刷新了之后再访问还是旧的内容、或者一会儿旧一会儿新、或者今天新的明天又是旧的,要解释这个现象就先来了解下CDN是怎么一回事儿。内容分发网络(CDN)其实是一组分布于全国(全球)各地的缓存代理服务器,当一个用户访问一个资源时,DNS把他解析到到离他最近的一台CDN服务器(节点)上;如果节点上没有资源,它会向源站请求,得到结果后缓存并返回;当下一个访问这个节点的用户再请求相同资源时,CDN节点直接返回缓存的内容而不再向源站请求直到缓存失效。知道了CDN的工作原理后就好解释了,全国(全球)有几百几千个CDN节点,每个节点可能又有很多很多的机器,要想跑一个任务就从这么多机器上把某个缓存失效掉,可能并不那么“简单”也不那么“可依赖”。
再假设即使 CDN 强制刷新缓存这步完美地完成了,那也仅仅停留在 CDN 节点上,还存在其他缓存的地方。某些运营商可能出于一些原因会架设代理服务器缓存内容(往往都不太靠谱),这是完全不可控的(幸好 https 可以解决这个问题)。多说一句,跟运营商代理类似的,某些浏览器号称的“云端加速”功能也是一丘之貉。以及前面说到的,用户第一次访问之后浏览器就缓存了内容,而且缓存有效期往往还挺长,除非用户手动清空浏览器缓存否则覆盖更新并不能及时地到达用户的设备上,而指望用户自己有事没事儿清理缓存几乎是不可能的。所以刷新 CDN 缓存其实是个玄学,你不知道缓存是不是真的被刷新了,无法证实也无法证伪;这一次访问到的资源是新的只能说明这次被解析到的CDN节点上的资源被刷新了或者没有缓存过内容,并不能得出其他CDN节点的缓存也全都被刷新了;这一次访问到的资源是过期的不能说明强制刷新CDN缓存失败了,可能是某层代理响应了过期的内容,谁知道呢?以及,刷新 CDN 缓存只对增量用户有效,存量用户已经缓存了过期内容,依旧无法获取更新。
鉴于这种情况,我们聪明的前端同学们当然也想出了一些强制刷新浏览器缓存的做法——比如在程序中给请求URL加时间戳——这也是不可取的。这种做法通过改变时间戳来控制缓存刷新的间隔,间隔时间通常只有几分钟或几小时,写死在代码逻辑中;也就是说,即使一个文件上线后几个月都没有变化过,这段逻辑也会使得用户可能每天都要下载好几遍完全相同的文件,可恶至极。正如上面提到的,如果某层代理开启了过滤 queryString,那么通过加参数来刷新代理缓存的方式就无效,这种做法的效果也就仅限于刷新本地缓存。至于 CDN 服务,当然不能也不应该把缓存时间设置成几分钟、几小时来满足覆盖更新的需求。
我们从浏览器发起请求出发,经过若干层代理到达源站,再从源站响应内容返回到浏览器,捋清了“从浏览器发起GET请求到接收到响应”中间过程的请求流向,知道了各层可能会如何缓存内容,以及响应内容可能来自各层缓存而不是源站。因此即使不从前端工程化的角度来看,仅仅是缓存这系列的烂摊子,也应当使得我们对“覆盖更新”这种方式有所警惕,主动拒绝。